Resources
This carefully curated collection of resources will help you find packages and learning resources to help you on your R journey.
Visualize Census Data in Maps at the Block Level with R
Bastián Olea nos guÃa en cómo visualizar los recientemente lanzados datos del Censo de Población y Vivienda de Chile de 2024 en mapas a nivel de manzana. En el tutorial, aprenderemos dos métodos para mapear datos censales: utilizando mapas estáticos con el paquete {ggplot2}, y creando mapas interactivos con {mapgl}. Se inicia con la descarga de datos cartográficos desde la página del INE y se procede a cargarlos con {arrow}. Finalmente, se preparan y visualizan los datos espaciales con {dplyr} y {sf} para generar visualizaciones detalladas y útiles.
Go to Resource
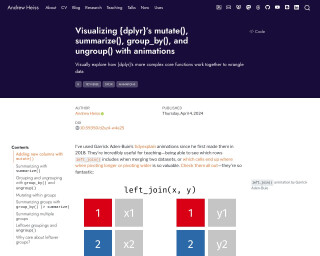
Visualizing {dplyr}’s mutate(), summarize(), group_by(), and ungroup() with animations
Andrew Heiss explores {dplyr} functions like mutate(), summarize(), group_by(), and ungroup() through handmade animations. Heiss illustrates the complexities of data manipulation workflow steps that are not immediately obvious when performing operations like adding new columns or summarizing data. This tutorial helps conceptualize the impact of these functions on data frames by visualizing their behind-the-scenes mechanics. The animations serve as an effective teaching tool to demystify what happens to data during different stages of the tidyverse's split/apply/combine paradigm, using handcrafted illustrations to make the learning process more intuitive.
Go to Resource
Vizualizing global testosterone levels by country
This article by Aspire Data Solutions outlines the process of web scraping testosterone levels for different countries from the World Population Review website and creating a choropleth map to visualize the data in R. It demonstrates how to gather, clean, and plot geographical data, cautioning that this ecological dataset is approximate, not age-standardized, and should be used for identifying patterns rather than for precise comparisons or causal inferences. The author, Mihiretu Kebede (PhD), also includes code snippets and explanations for the R packages used.
Go to Resource
Voice control ggplot2 with ggbot2
Stephen Turner introduces ggbot2, a tool for controlling ggplot2 visualizations with voice commands. By installing ggbot2 from the tidyverse GitHub repository, users can launch a Shiny app to interact with the mtcars dataset. Voice commands enable actions like creating scatter plots, adjusting colors and sizes of points, switching themes, and reverting changes. The user-friendly ggbot2 enhances data exploration with a hands-free, efficient approach to crafting ggplot2 charts, making data visualization more accessible and interactive.
Go to Resource
vroom
vroom is a package in R that provides the fastest delimited reader. It uses lazy loading and multiple threads for improved performance. It supports various parsing features, such as delimiter guessing, custom delimiters, column types specification, and more.
Go to Resource
W. Joel Schneider
This text demonstrates the usage of arrow geometries in ggplot2 for creating custom arrowheads.
Go to Resource
Welcome to ModernDive (v2) | Statistical Inference via Data Science
ModernDive (v2) is the website for 'Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition)'. It showcases updates from the first edition, which is available online and for purchase. The book, authored by Chester Ismay, Albert Y. Kim, and Arturo Valdivia, teaches R and data science concepts. It's scheduled for print by CRC Press in 2025 and is licensed under Creative Commons. Readers can contribute on GitHub and anticipate a resource-rich approach to stats with a focus on tidyverse tools for data analysis.
Go to Resource
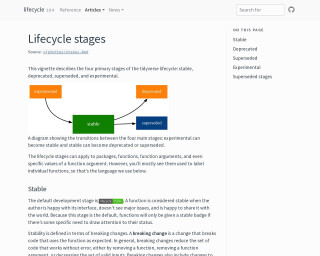
What does deprecated mean? Package lifecycle and the process of deprecation
This content describes the lifecycle stages of the tidyverse ecosystem, including stable, deprecated, superseded, and experimental stages, mainly as they apply to functions. It outlines how the stages affect the usability and changes in functions, with a focus on preventing and managing breaking changes. Emphasis is placed on ensuring code robustness by careful use of functions according to their intended effects. The content also addresses the gradual deprecation process, which provides warnings and guidance for replacing outdated functions, and introduces the 'lifecycle' package for managing these transitions.
Go to Resource
What does deprecated mean? Package lifecycle and the process of deprecation. - YouTube
This YouTube video provides an explanation of the meaning of 'deprecated' and discusses the package lifecycle and the process of deprecation.
Go to Resource
What is Takes to Tidy Census Data
This article explains the process of tidying Census data using R and tidyverse packages.
Go to Resource
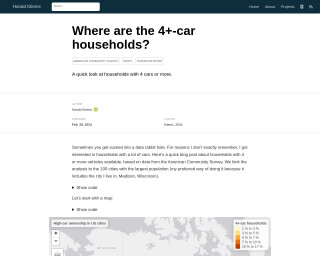
Where are the 4+-car households?
Harald Kliems investigates the prevalence of 4+-car households in the 100 most populous US cities using data from the American Community Survey. The blog post highlights the spatial distribution of such households and contrasts the top and bottom ten cities in terms of the percentage of 4+-car ownership. Key R packages used in the analysis include tidyverse, tidycensus, tigris, gt, and tmap. This examination into the facets of American car ownership is accompanied by visualizations such as maps and tables, enabling deeper insights into the data.
Go to Resource
Which names that are also names of countries are most common?
Simon P. Couch's blog post investigates which names that are also names of countries are most popular in the United States from 1880 to 2017. The post details the process of using R and packages like 'babynames' and 'countrycode' to filter and analyze baby name data. It offers a glimpse into the results, revealing the top country-names and their trends over time. Readers are encouraged to guess the most common names before seeing the data-driven answer. The post concludes with interesting visualizations showing the historical trends for the top country-names.
Go to Resource